

(Dieser Artikel erschien zuerst im Print-Übersteiger 131 am 10.März 2018. Er ist der zweite Teil einer kleinen Taktik/Statistik-Serie hier im Blog, Teil 1 findet Ihr hier.)
Big Data im Fußball – Die Suche nach der Fußball-Matrix
Der Fußball erlebt eine krasse digitale Revolution durch die Aufzeichnung von Positionsdaten der Spieler während der Partien. Konservative Medien und Blogs versuchen aus den Massen an inzwischen zur Verfügung stehenden Daten bessere Kenngrößen für die Spielbeschreibung zu entwickeln. Wettanbieter wollen anhand der Daten ihre Vorhersagemodelle verbessern und Vereine wollen damit ihre Mannschaft so gut es geht auf den Gegner einstellen und bestmögliche Transfers tätigen. Wird die Nutzung dieser Daten den Fußball massiv verändern?
Statistiken sind im Fußball ein gern gebrauchtes Mittel um die Stärken und Schwächen von Mannschaften und Spielern zu ermitteln. Doch welche Statistiken sind aussagekräftig genug, um die wirkliche Stärke eines Teams zu beschreiben? Vor wenigen Jahren wurde in der Bundesliga begonnen, die Möglichkeiten der digitalen Revolution zu nutzen: Inzwischen werden hochaufgelöst Positionsdaten aller Spieler erfasst. Bei 25 Kamerabildern pro Sekunde, 5400 Sekunden pro Spiel und 22 Fußballern inklusive Spielgerät ergibt das satte 3,1 Millionen Positionsdaten pro Spiel. Zusätzlich werden über die gesamte Saison etwa 500.000 Pässe, 150.000 Zweikämpfe und 17.000 Torschüsse und 6.000 Ecken und viele weitere Parameter in beiden Bundesligen erfasst. Diese Daten werden den Bundesligisten von der DFL zur Verfügung gestellt. Viele Daten werden komplett automatisch erhoben, allerdings basieren einige Parameter auf subjektiven Einschätzungen. Die Auswertung solcher massigen Datensätze ist ohne Informatik-Hintergrund kaum zu bewältigen. Doch welche Aussagen lassen sich aus solchen Daten überhaupt ableiten?
Fußball – ein hochkomplexer Sport
Andere Sportarten haben es auf dem Gebiet der Spielanalyse leichter. Vor allem wenn sich, wie im American Football oder Baseball, Standardsituation an Standardsituation reiht. So ist es nicht weiter verwunderlich, dass der erste große Erfolg mit statistik-basierten Spielertransfers im Baseball stattfand. Die Oakland Athletics wurden unter der Leitung von Billy Beane Anfang des Jahrtausends trotz geringem Budget vom Underdog zu einem der Top-Teams der Liga geformt. Und es gibt auch Versuche, Transfer- und Taktikentscheidungen bei Fußballklubs alleine auf Grundlage von Daten zu tätigen. Der Physiker Matthew Benham machte einst ein Vermögen mit modell-basierten Sportwetten. Nun versucht er den FC Brentford in die englische Premier League zu führen. Nebenbei feierte er mit dem FC Midtjylland, quasi sein Nebenprojekt, 2015 den dänischen Meistertitel. Transfer- und Taktikentscheidungen werden bei beiden Klubs maßgeblich von KPIs, sogenannten Key Performance Indikatoren bestimmt. Welche KPIs das genau sind, lassen sich die Verantwortlichen beider Klubs nicht entlocken, der vermeintliche Wettbewerbsvorteil soll erhalten werden. Allerdings: Seit der erfolglosen Teilnahme an der Aufstiegsrunde 2015 dümpelt der FC Brentford im grauen Mittelfeld der zweiten englischen Liga herum. Auch der FC Midtjylland zeigte nach der Meisterschaft, dass die Kurve nicht nur steil nach oben zeigt, ist aber inzwischen wieder dick im Rennen um die dänische Fußballkrone vertreten. Der Erfolg von rein modell-basierten Entscheidungen im Fußball scheint also mindestens schwieriger als in anderen Sportarten zu sein. Zu dynamisch und komplex sind die Spielsituationen, zu situativ und daher wenig planbar die Entscheidungen der 22 Akteure auf dem Spielfeld. Es ist also nicht weiter verwunderlich, dass eine datengetriebene Verbesserung des FC Midtjylland vor allem in Standards deutlich wurde, da diese Situationen im Spiel am besten planbar sind.
Bisherige Statistiken nahezu unbrauchbar
Wo kein einfacher Weg ist, bleibt viel Raum zur Entfaltung: Die Blog-Landschaft zu Fußball-Statistiken, aber auch die Sportwissenschaft können momentan als „El Dorado“ für neu entwickelte Kenngrößen bezeichnet werden. Die Positionsdaten sind je nach Anbieter um verschiedene Parameter ergänzt. Nahezu wöchentlich werden neue Kenngrößen für die Beschreibung der Qualität von Mannschaften und Spielern in den Ring geworfen. Es werden verschiedene Datensätze miteinander kombiniert, modelliert, gewichtet und interpretiert. Interessenten für Kenngrößen, die die Qualität von Spielern oder Mannschaften beschreiben, gibt es viele. Zum einen möchten die Wettanbieter ihre Vorhersagemodelle präzisieren. Die Vereine haben großes Interesse an der Weiterentwicklung der Spielanalyse mittels Positionsdaten und weiterer Parameter. Ganz grundsätzlich sind die deutlichsten Veränderungen durch die Analyse großer Datensätze in den Klubs im Scouting zu erkennen. Dank der Datenanalyse können tausende von Spielern in kurzer Zeit miteinander verglichen werden ohne dass die Scouts rund um den Globus reisen und unzählige Spiele im Video anschauen müssen. Das spart enorme Kosten in den Klubs und führt zu einer viel höheren Effektivität. Die Menge der Daten muss nur erst einmal verarbeitet werden. Manchester City, besser bekannt als König Protz des Fußballs, machte die Positionsdaten seinen Fans zugänglich um aus den Unmengen an Daten die relevantesten herauszufiltern. Kaum eine Rolle spielen hingegen die von vielen Medien geliebten Statistiken wie die reinen Laufstrecken, die Ballbesitzverhältnisse, Passquoten und Zweikampfwerte. Selbst das reine Torschussverhältnis ist ohne die Nutzung weiterer Parameter nur bedingt aussagekräftig. Viel mehr Aussagekraft können diese Daten aber dann liefern, wenn sie gekonnt mit den Positionsdaten kombiniert werden.
Es gibt erfolgreiche Pässe und erfolgreichere Pässe
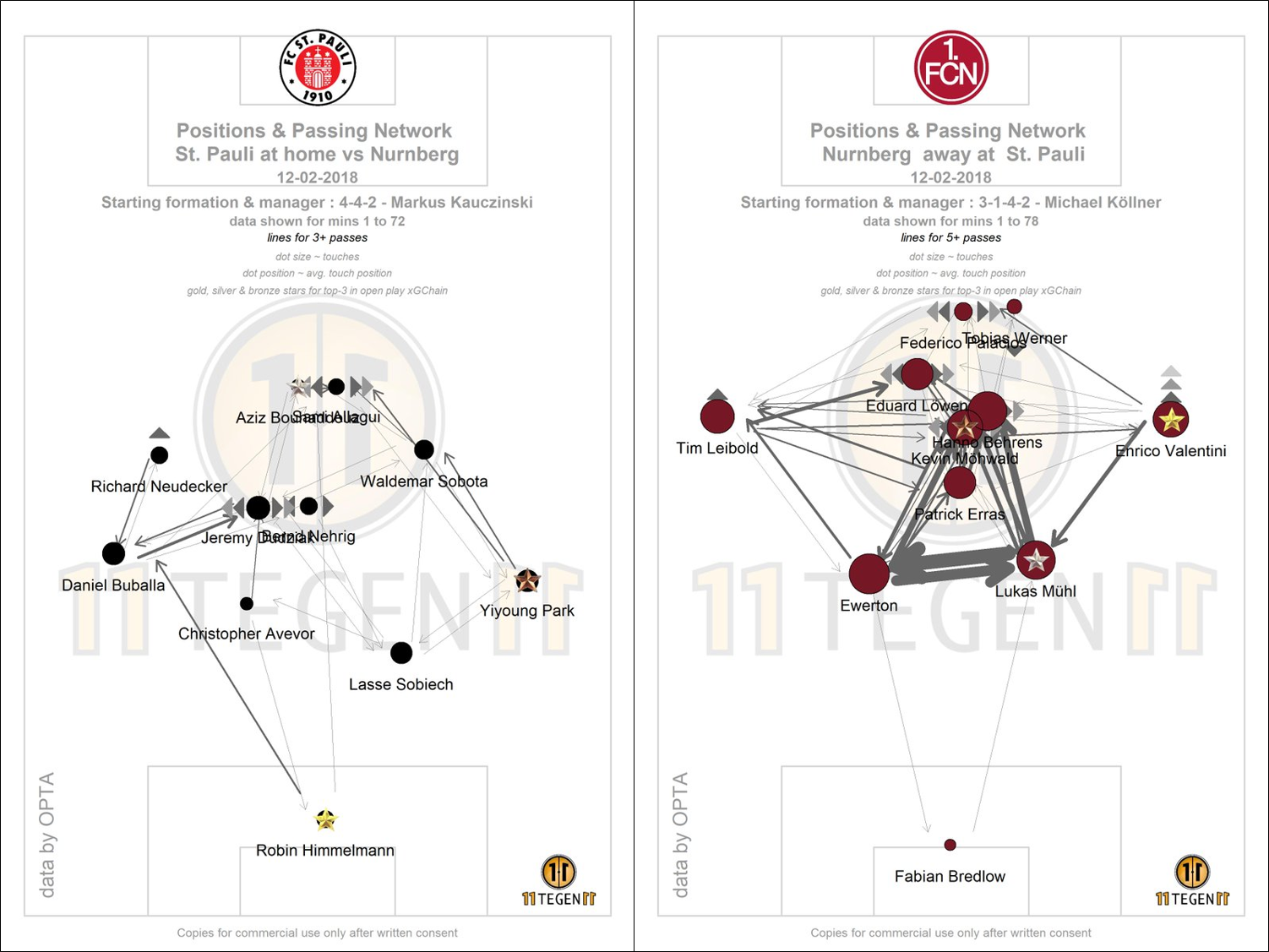
Klar, ein Pass ist dann gut, wenn er beim Mitspieler ankommt. Aber es ist einleuchtend, dass ein erfolgreicher Pass qualitativ höher bewertet, wenn er tief in der gegnerischen Hälfte an den Mitspieler gebracht wird im Vergleich zu erfolgreichen Quer- oder Rückpassen. Als Beispiel dient das ehemalige Duo in der Innenverteidigung des BVB, Mats Hummels und Neven Subotic. Hummels ist bekannt für seine Weltklasse im Aufbauspiel, Subotic eher wegen seines guten Stellungsspiels und Zweikampfverhaltens. Die bessere Passquote wies jedoch meist Subotic auf. Eine Auswertung der gespielten Pässe ergab, dass Hummels eher risikoreiche tiefe, Subotic eher risikoarme Quer- und Rückpässe spielte. Durch das höhere Risiko ergab sich eine schlechtere Passquote bei Hummels, wenn er die tiefen Pässe aber an den Mitspieler brachte, sorgte diese Spieleröffnung meist für Torgefahr. Ein erfolgreich gespielter Pass ist daher unterschiedlich zu bewerten, je nachdem wo auf dem Spielfeld und unter welchem Gegnerdruck er gespielt wurde. Der ehemalige Fußballer Stefan Reinartz hat mit seinem Kollegen Jens Hegeler den „Packing“-Ansatz entwickelt. Hierbei wird anhand der Positionsdaten berücksichtigt, wie viele Gegner mit Pässen erfolgreich überspielt werden. Ungekrönter König dieser Statistik ist Toni Kroos, der deshalb unlängst gehaltsmäßig mit Flügelflitzer Gareth Bale und Real-Größe Sergio Ramos auf eine Ebene gehievt wurde, obwohl es seinem Spiel an spektakulären Elementen mangelt.
Für Vereine ebenfalls interessant sind Visualisierungen der gespielten Pässe, die in Kombination mit den Positionsdaten erstellt werden können. Diese Pass-Graphiken zeigen selbst in vereinfachter Form die wichtigsten Passwege von Teams an. Eine Analyse also, die im Videostudium Stunden und Tage frisst. Die zentralen Passwege des Gegners können so recht schnell analysiert und je nach Matchplan zugestellt oder als Pressingsignal genutzt werden. Besonderes Augenmerk legen Spielanalysten auch auf die Abstände zwischen den Ketten oder zwischen Abwehr und Mittelfeld. Lässt sich aus der Analyse erkennen, dass ein Außenverteidiger immer länger braucht bis er beim Verschieben mit ins Zentrum einrückt, so ist eine potenzielle Lücke im massiven Abwehrverbund aufgedeckt, die bespielt werden kann. Auch hierbei kann die Analyse aufgrund der Positionsdaten wesentlich schneller durchgeführt werden.
In Zukunft „expected Goals“ statt einfacher Torschussverhältnisse?
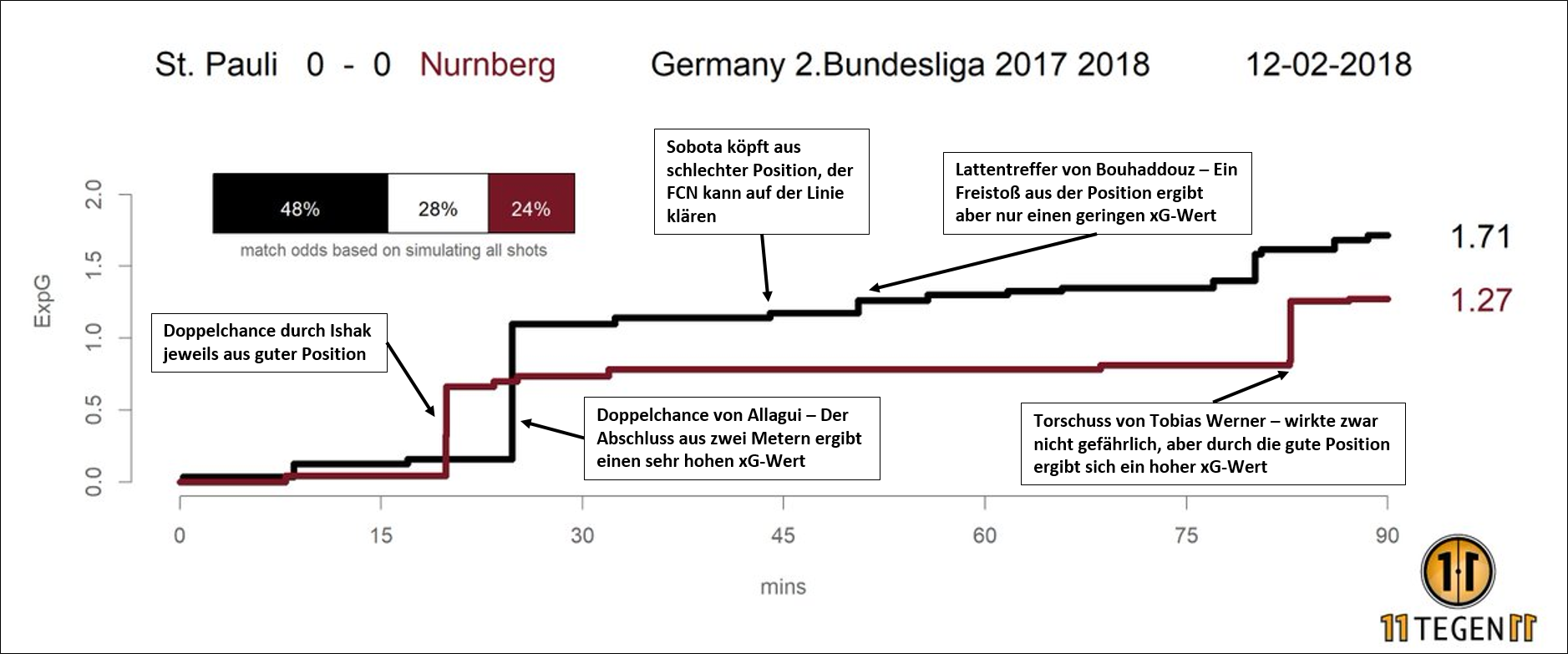
Der „Poster-Boy“ der modernen Fußball-Statistik sind zweifelsohne expected Goals, auf Deutsch auch verdiente Tore genannt (kurz xG). Während in die übliche Torschuss-Statistik alle abgegebenen Torschüsse gleichermaßen eingehen, werden hier die einzelnen Torschüsse mit Zahlen zwischen 0.01 und 1 gewichtet, mit niedrigen Zahlen bei Torschüssen die statistisch selten und hohen Zahlen bei Torschüssen, die häufig zu Toren führen. Ein Elfmeter wird z.B. mit 0.75 bewertet, da 75% aller Elfmeter zum Torerfolg führen. Um die Wahrscheinlichkeit eines Tores durch einen Torschuss zu berechnen, werden eine Menge Daten benötigt. Zum einen die Positionsdaten, um zu erkennen aus welcher Position geschossen wurde. Zum anderen werden Daten zu anderen Torschüssen benötigt, um die Wahrscheinlichkeit des Torerfolgs von Torschüssen aus bestimmten Positionen zu berechnen. Aus einem Torschussverhältnis von 25:13 ergibt sich so ein xG-Verhältnis von 1.5:1.7 (wie beim 3:1 Auswärtssieg des FCSP bei der SGD). Wenn also ein Team aus allen Rohren feuert, sich aber auf Fernschüsse beschränkt, so wird die konservative Torschuss-Statistik in die Höhe schnellen. Der xG des Teams bleibt jedoch gering im Vergleich zu einem Team, das sich wenige, aber dafür „100-Prozentige“ herausspielt. Die expected Goals stellen daher ein aussagekräftiges Tool zur Beschreibung der Tore dar, die ein Team anhand seiner Torschüsse verdient hätte und daher ein Indikator für die Stärke eines Teams. Es gibt aber einen Nachteil bei der Datenaufzeichnung: xG-Modelle kommen nicht ohne menschlichen Input aus. Für die Beurteilung der Qualität einer Torchance ist nämlich mehr als die Position der Spieler notwendig. Es müssen auch die Qualität der Vorlage und der Gegnerdruck während des Torschusses bewertet werden, denn ein halbhoch und scharf gespielter Ball ist sehr viel schwerer zu verwerten als ein perfekt getimter Flachpass und umzingelt von mehreren Gegenspielern ist ein Abschluss ungleich schwieriger als wenn man allein vor dem Tor steht. Besonders aussagekräftig bezüglich der Stärke eines Teams werden die xG-Werte, wenn diese mit erfolgreichen Pässen im gegnerischen Drittel kombiniert werden, wie es die Pioniere der xG-Modelle vom Fußball-Blog 11tegen11 machen. Hierbei werden angekommene Pässe tief in der Hälfte des Gegners gezählt. Diese nicht-schuss-basierte Kenngröße fließt bei einigen anderen xG-Modellen (es gibt inzwischen unzählige) bereits mit in die Ermittlung des Wertes ein.
Da mit xG-Werten eine Kenngröße entwickelt wurde, die die Qualität der Torchancen zueinander vergleicht, kann auch die Qualität der Protagonisten zueinander verglichen werden. Es kann bestimmt werden, wie viele Tore ein Stürmer anhand seines individuellen xG-Wertes hätte erzielen müssen, wie viele Tore mehr oder weniger man sich dank des eigenen Torhüters fängt und zu welcher Chancenqualität die Torschussvorlagen einzelner Spieler führen. Es ist zu erwarten, dass, sobald es einen haltbaren Konsens über die Eingangsvariablen der xG-Modelle gibt, die xG-Werte die bisherigen Torschussstatistiken in der medialen Berichterstattung ersetzen, vorausgesetzt, die Dateneingabe wird weiter automatisiert.
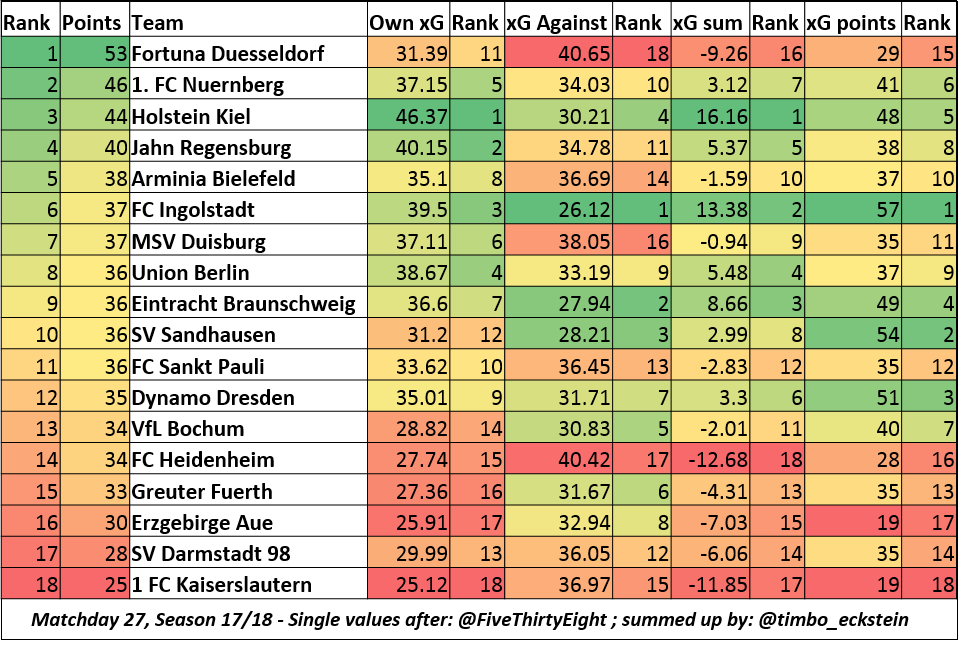
Tore nach Ecken fallen statistisch je Team nur alle 15,4 Spiele
Die Positionsdaten können aber noch viel mehr als mit ihrer Hilfe die Qualität von Pässen und Torschüssen zu beurteilen. Die Forscher Jürgen Perl aus Mainz und Daniel Memmert aus Köln haben mit ihrer Firma „soccer“ verschiedene Algorithmen entwickelt um aus den Positionsdaten die taktischen Muster der Angreifer und Verteidiger automatisch zu erkennen. Hierbei kann unter Hinzunahme anderer Parameter wie Ballgewinn oder Torschuss ermittelt werden, welche taktischen Muster gegen welche Formationen effektiv sind. Die Kenntnis darüber ist elementar, da die Teams inzwischen ihre Formationen mehrmals während eines Spiels je nach Spielsituation und Spielstand anpassen. Ein weiterer Ansatz der beiden Forscher basiert auf Voronoi-Zellen, einem Analyseansatz zur Unterteilung von Räumen in Sektoren. Hiermit kann sekündlich auf dem Spielfeld die Raumkontrolle beider Teams errechnet werden, also die Bereiche, in denen ein Spieler schneller als die Gegenspieler einen Pass erreicht. Die Raumkontrolle in Kombination mit Ballkontrolle ergibt dann die Spielkontrolle. Diese Art der Spielanalyse stellt die Schnittstelle zwischen Fußballverstand und Informatik dar. Der Bedarf an solch speziell ausgebildeten Spielanalysten ist so groß, dass das Fach „Spielanalyse“ inzwischen in Köln studiert werden kann.
Fernab der großen Datenmengen sind mit verschiedenen Analyse-Werkzeugen viele weitere Erkenntnisse möglich. Beispiele? Es wurde z.B. errechnet, wann bei eigenem Rückstand Einwechslungen am sinnvollsten sind (1.Wechsel vor der 58.Minute; 2.Wechsel vor der 73.Minute und letzter Wechsel vor der 79.Minute) und dass Ecken vollkommen überbewertet werden (im Schnitt erzielen Teams nur alle 15,4 Spiele ein Tor nach einer Ecke). Der AC Mailand erlangte mit seinem „Milan Lab“ bereits vor etwa 10 Jahren Berühmtheit. Unter anderem mittels neuronaler Netze wurde versucht, die Verletzungen der eigenen Spieler zu minimieren und es konnten so im Jahre 2008 etwa 90% der Verletzungen ohne Fremdeinwirkung verhindert werden.
Die Diskussion um die Nutzung dieser Datensätze für taktische Zwecke ist hochemotional. Kürzlich sorgte Ex-Kicker und Ex-TV-Experte Mehmet Scholl mit heftiger Kritik an der Generation „Laptop-Trainer“ für Aufsehen. Er monierte, dass Jugendspieler keine Hinweise mehr bekämen, warum Pässe oder Dribblings nicht gelingen, stattdessen aber „18 Systeme rückwärts furzen“ könnten. Eine ganze Reihe von Experten und Spielern äußert sich daraufhin in die entgegengesetzte Richtung. Allerdings können diese Experten nicht leugnen, dass alle Analyse eben nur dann sinnvoll ist, wenn es letztlich zum Erfolg, also zu Toren führt. Doch gerade hier gibt es einen gewaltigen Haken, wie Martin Lames von der TU München herausgefunden hat: Etwa 45% aller Tore kommen eher glücklich zustande. Glücklich bedeutet in diesem Fall, dass der Ball entweder abgefälscht wurde oder unter Zuhilfenahme von Latte oder Pfosten oder aus großer Entfernung den Weg ins Tor gefunden hat. Das Toreschießen selbst kann also getrost mit dem Würfeln verglichen werden. Ziel von Analysten, Trainern und Sportdirektoren sollte es also sein, die großen Datensätze so zu nutzen, dass man häufiger würfeln darf als der Gegner. // timbo